資料工程師轉職專題:挑戰與難點
目錄
Airflow 挑戰(一):迴圈流程
這個問題發生在要將爬蟲程式轉換成Airflow的dag程式時遇到的。由於專題的資料涉及許多「縣市」、「行政區」、「店家類別」、「寵物類別」、「日期」等參數的變化,所以在起初撰寫爬蟲時,我使用了多個迴圈來處理這些參數,可以快速的掃過所有排列組合。例如:
# 以日期作為啟動條件,接著搜尋所有城市與寵物類別的排列組合
while start < today:
for city in city_list:
for animal in animal_list:
## 爬蟲程式邏輯.
## 爬蟲程式邏輯..
## 爬蟲程式邏輯...
## 且變數可以多次使用,例如存檔檔名
file_name = f"{start}_{city}_pet.csv"
這樣的寫法方便又快速,但是在編寫dag程式時卻行不通。原因如下:
- 在dag中是以函式作為pipeline的節點,如果要為完整流程設立節點,就必須將程式拆成多個函式。
- 但是迴圈本身是一個不可拆分的流程,一旦執行就是完整的一圈,無法把單次迴圈再切成上半和下半,也沒辦法切成前10圈和後10圈。
- 所以如果要在dag中使用迴圈,那整個迴圈就只會有一個節點。這樣的問題是:如果中途出錯了就必須從第一圈重跑,這就失去了Airflow錯誤重試的特點。
解決方法
我的解法意外的單純:放棄迴圈,改為各自獨立的流程。Airflow是支援平行處理的,所以可以將原本的每一圈都獨立成單獨的流程,當所有流程都完成,再將資料合併成一個檔案或DataFrame做後續處理。有兩種寫法可以達到相同的效果:
寫法一:土法煉鋼
data_NTP_dog = S_create_post_data(dict_name=data_dict_NTP, ani="0")
data_NTP_cat = S_create_post_data(dict_name=data_dict_NTP, ani="1")
data_TPE_dog = S_create_post_data(dict_name=data_dict_TPE, ani="0")
data_TPE_cat = S_create_post_data(dict_name=data_dict_TPE, ani="1")
data_TYN_dog = S_create_post_data(dict_name=data_dict_TYN, ani="0")
data_TYN_cat = S_create_post_data(dict_name=data_dict_TYN, ani="1")
data_TCH_dog = S_create_post_data(dict_name=data_dict_TCH, ani="0")
data_TCH_cat = S_create_post_data(dict_name=data_dict_TCH, ani="1")
data_TNA_dog = S_create_post_data(dict_name=data_dict_TNA, ani="0")
data_TNA_cat = S_create_post_data(dict_name=data_dict_TNA, ani="1")
data_KSH_dog = S_create_post_data(dict_name=data_dict_KSH, ani="0")
data_KSH_cat = S_create_post_data(dict_name=data_dict_KSH, ani="1")
上述的寫法簡單粗暴,就是將程式碼重複編寫,只是帶入不同參數,好處是不會有什麼問題,只是寫好後最好再次檢查,如果用複製貼上容易有漏換的參數。另一個缺點是看起來冗長,視覺化流程圖也會看起來很龐大複雜。
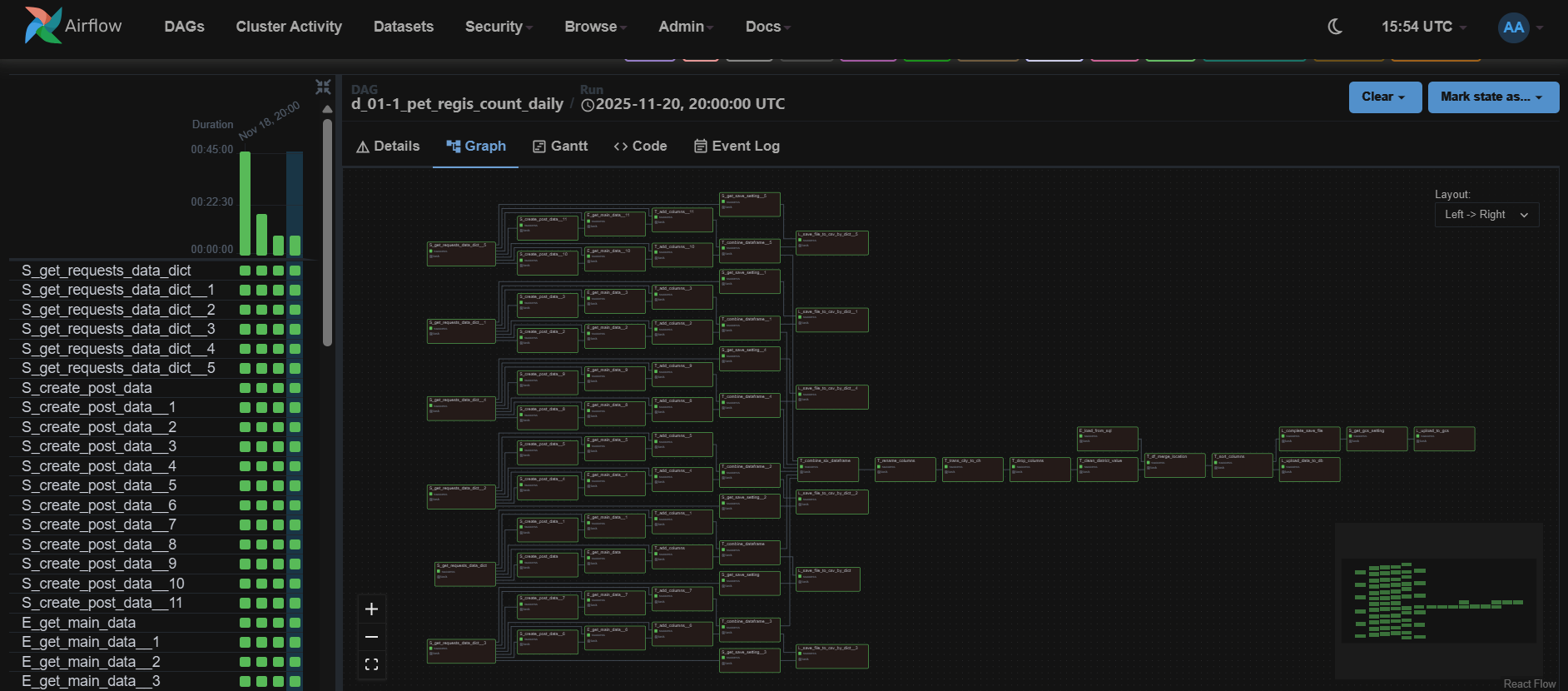
寫法二:動態映射
index_list = [0, 1, 2, 3, 4, 5]
data_dict = S_get_requests_data_dict.expand(city_index=index_list)
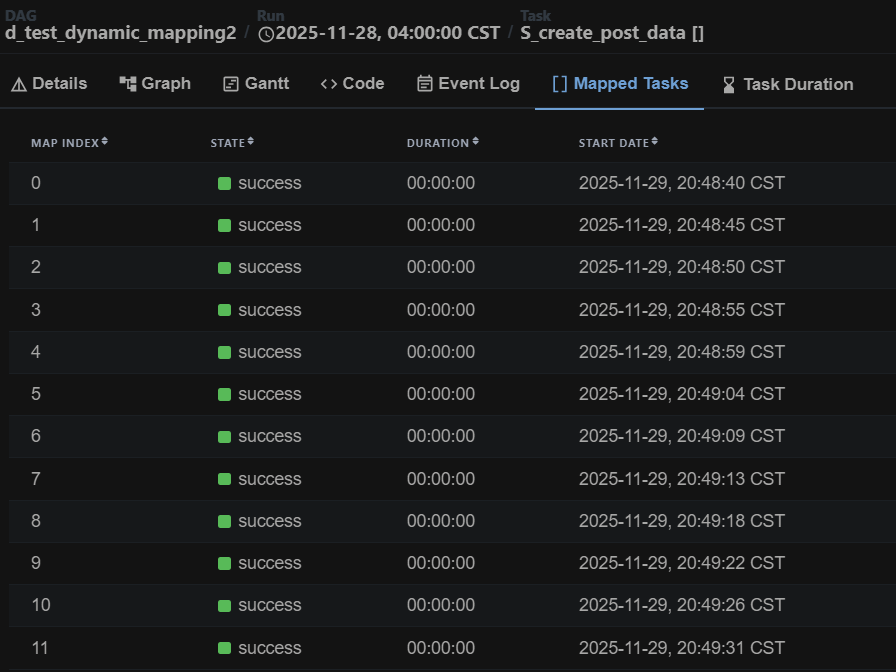
這是dag中另一個比較簡潔的寫法,將要帶入的參數設成list,然後在函式後面加上.expand()。Airflow會自動將list中的參數依序帶入函式,並且將得到的回傳值也依序存成列表,所以在上述例子中的data_dict會是一個list存放6個物件。
流程圖會變得很單純,都只有單一節點,節點名稱的後面會標註數字代表這個節點裡面有幾條平行處理的流程。
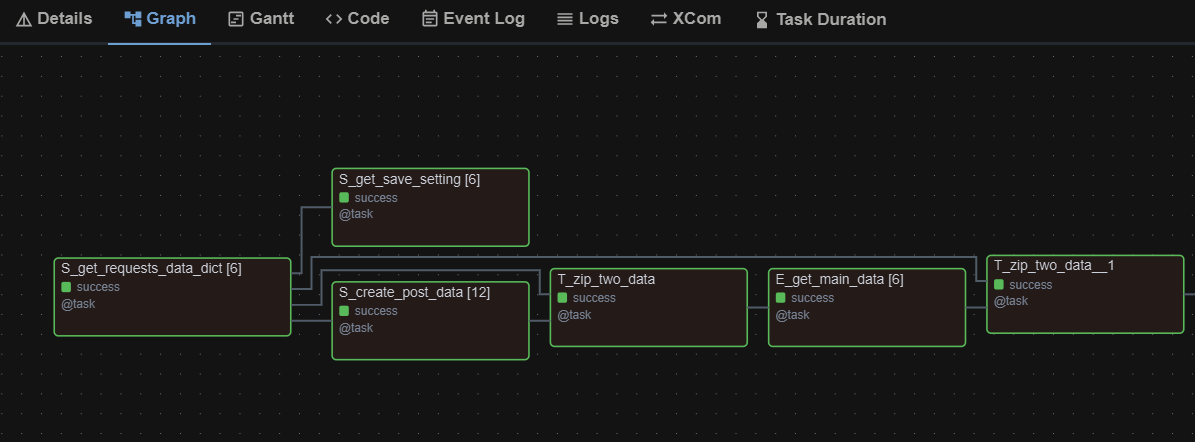
但這樣的寫法需要注意:
- 若使用
.expand()且帶入參數為多個list的話,Airflow會產生list長度相乘後相等數量的平行處理。 - 如果想要將參數兩兩一組帶入函式,需要先將兩個list拆解重組成tuple再用
.expand()。
index_list = [0, 1, 2, 3, 4, 5]
animal_list = ["0", "1", "2", "3", "4", "5"]
data_loc_ani = S_create_post_data.expand(
dict_name=index_list,
ani=animal_list
)
如果是上述的寫法會產生6*6=36條平行處理的流程,如果是希望index_list和animal_list兩兩一組帶入函式就好(這樣只會有6條平行處理的流程)需要先將list重組成tuple:
index_tuple = [(0,0), (1,1), (2,2), (3,3), (4,4), (5,5)]
data_loc_ani = S_create_post_data.expand(data_dict=index_tuple)
Airflow挑戰(二):SQLAlchemy相容性
雖然當初在建立測試環境時就有預想到可能會遇到相容性問題,但還真沒有想到竟然是SQLAlchemy出問題。或許是Airflow本身必須依賴資料庫運行,連結的方式就是透過SQLAlchemy,所以對於SQLAlchemy的要求也特別嚴格。
我們使用的Airflow是2.x版,因為在當時3.x版還算很新,一方面可能還有一些相容性問題,另一方面對於大部分的既有團隊應該都還是使用2.x版,所以我們選擇比較普及的版本。而SQLAlchemy當時最新版應該是2.0.44版,如果先起好Airflow容器再安裝最新版的SQLAlchemy,雖然當下似乎沒有問題,但是將容器關閉重啟後,會發現容器不斷崩潰重啟。
如果安裝SQLAlchemy時不指定版本,讓pip自行處理相容性問題,那應該會安裝到1.4.54版,雖然容器可以正常重啟和運行,但換成SQLAlchemy出問題。不管是用常用的df.to_sql(con=engine)或df = pd.read_sql(sql, con=engine)都會出現engine has no attribute 'cursor'的錯誤訊息。
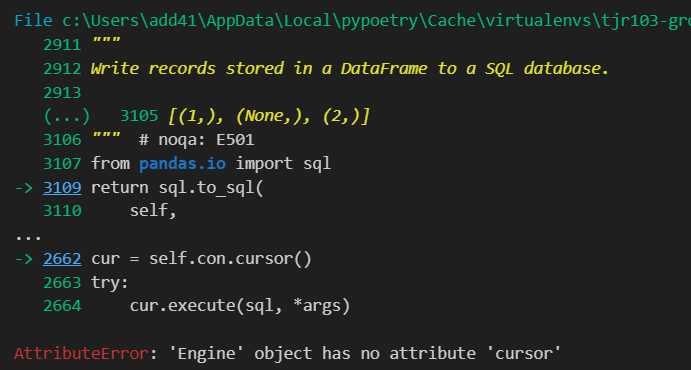
這個問題到最後也沒能解決,嘗試了許多的寫法,有的需要去底層呼叫.connect(),反而失去SQLAlchemy寫法簡潔的優點,而且還是有某些情況會報錯。最終礙於時間限制,我們就決定改用PyMySQL。
Airflow挑戰(三):參數傳遞
Airflow的底層不是純Python,所以在傳遞參數時不如Python自由,很常遇到原始程式碼可以傳遞,但寫成dag程式就會報錯。
Airflow在dag中傳遞參數時需要將參數序列化,所以通常只能傳遞基本的字串、數字、布林,或可序列化的list、dict、JSON資料,且參數往往要在函式內部才能使用索引,df = read_df_from_file(file=info[0])這樣的寫法是很容易報錯的,因為此時info是一個序列化物件,沒辦法直接用[0]方式進行索引。
其實這部份我並沒有搞得非常清楚,有的寫法大部分時候會報錯,但偶爾又能夠執行。此外雖然DataFrame被歸類為複雜物件,但實際上卻可以在函式之間傳遞,而當資料筆數大到一個程度時似乎又會報錯。
最後我最常用的寫法其實是用dict帶參數,因為dict可以輕易被傳遞,又可以同時帶多個值,且key值是可以解讀的(list只能用索引,一旦忘記就會讀得很痛苦)將dict作為一個參數包直接丟進函式,再在函式中根據key取value來使用。
雲端架構:資安議題
某一天我在為Airflow感到頭痛時,突然收到Google來信,告知我的GCP專案中的VM被偵測到可疑的活動,目前已經被停止了。頓時感到心頭一緊,趕緊上線查看,首先先查看VM的CPU使用率監控報告:原本使用率極低,某個時間點突然飆高且維持在100%左右,的確非常奇怪。
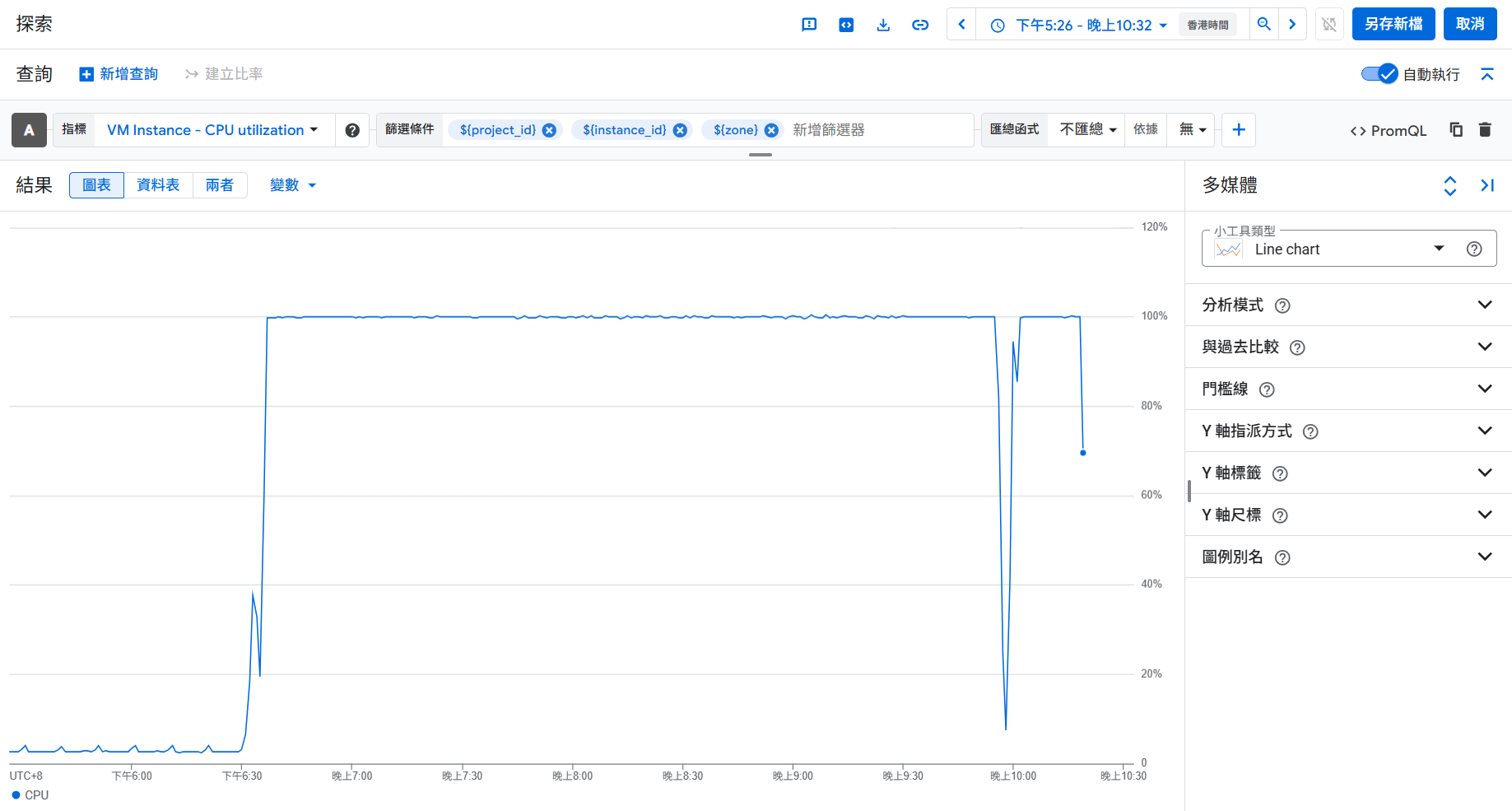
我將這個情況與做資安的朋友討論,結論是很可能遭到攻擊了。我將原本的VM直接砍掉(還好還沒正式部署)另外起了一台VM,並且作了一些措施:
-
在防火牆政策中拒絕icmp連線
icmp連線通常用於測試、監控,但也可能成為外部攻擊的缺口。考量我們目前沒有這個需求,所以就設為全部拒絕(GCP預設是全部允許)。 -
減少開放port號
原本為了便利,我在VM內使用了檔案瀏覽器、docker容器管理氣這類的工具,但相對就需要開放port號才能使用。被攻擊後則只安裝必要的服務和工具,降低被攻擊的機率。 -
設定監控規則
使用GCP的監控與警告工具,若未來再次出現CPU使用率突然飆高的情形,我會馬上收到通知,就可以更即時的上線處理。
經過這些處理後一直到專案完成,雲端就沒有再出問題了。
結語
以上就是我在這次專案開發過程中,遇到的一些比較棘手、意料之外的技術問題,這些問題往往跟底層架構有關,不單單只是「換一個寫法就好了」的問題,需要不斷的試錯、修正。
這也是我在開發過程中花最多時間的部分,爬蟲或ETL時固然也有許多小挑戰,但往往找到其規律及寫法後就能迎刃而解。但對於工具或系統的問題,除了不斷嘗試之外沒有別的方法。所以記錄此文,希望未來遇到相同問題能更快解決。
最後編輯於 2025-12-03