資料工程師轉職專題:細節盤點
作為第一個經過完整開發流程的專案,我已經撰寫兩篇文章說明專案的特點與開發遇到的困難與挑戰。最後我想更細節的分享這個專案的各個環節,我們所做的決定和一些細節。我想這篇文章會更偏向「紀錄」,所以並未有太多的技術價值,但若你正好有需要可以作為參考。
目錄
相關連結
概述
本專案(相關閱讀:《六都寵物資源分析開發實錄》、困難與挑戰)旨在透過蒐集六都寵物店家資訊,分析資源分布與商業潛力,並以視覺化儀表板呈現。
作為一個 End-to-End 的資料工程專案,我們建立了一套自動化的 Data Pipeline,涵蓋爬蟲、ETL、資料倉儲、分析到視覺化。
技術棧
| 領域 | 工具/技術 | 用途 |
|---|---|---|
| 資料獲取 | Python Script, Google Maps API | 網站爬蟲與 API 串接 |
| ETL/ELT | Python (Pandas) | 資料清洗、轉換與格式化 |
| 資料庫 | MySQL (GCP Cloud SQL/VM) | 關聯式資料庫儲存 |
| 自動化排程 | Apache Airflow | 工作流調度與監控 |
| 雲端 & DevOps | GCP (Compute Engine), Docker | 雲端基礎設施與容器化部署 |
| CI/CD | GitHub Actions | 自動化部署 |
| BI 視覺化 | Tableau | 互動式儀表板製作 |

專案選題
- 動機:團隊成員身為飼主,發現網路上缺乏整合性的各地區寵物資源數據,因而萌生開發念頭。
- 方法:定義六大寵物資源類別,蒐集六都各行政區的店家資訊,進行統計分析,量化「寵物便利度」與「商業潛力」。
- 核心價值:
- 飼主端:建立持續更新的寵物資訊站,便於按地區查找資源。
- 政府端:提供資源分布差異的量化數據,作為政策決策依據。
- 商業端:協助業者評估各地區的開店飽和度與潛力。
資料爬蟲策略
- 資料來源
- 政府公開資料:透過 Python 爬蟲獲取基礎數據(如寵物登記數)。
- Google Maps API:針對缺乏統一來源的店家資訊,利用 API 進行廣泛搜索。
- 規模與頻率
- 資料量:累積超過 11,000 筆店家資訊。
- 更新頻率:登記數(日更)、店家資訊(月更)。
- 地理半徑搜尋邏輯 為確保資料覆蓋率,我們採用「地理半徑搜尋」策略:先劃定目標縣市的地理邊界,再依據半徑設定多個搜尋中心點(座標),確保搜尋範圍完整覆蓋該行政區。
資料庫設計
- 基礎設施:部署於 GCP VM 上的 MySQL 實例。
- 建模策略:採用關聯式資料庫 (RDBMS) 設計,並進行正規化 (Normalization)。將原始資料拆解為事實表與維度表,透過 Foreign Key 維持資料一致性,減少冗餘。
資料表架構
本專案採用類似 星狀綱要 (Star Schema) 的設計概念:
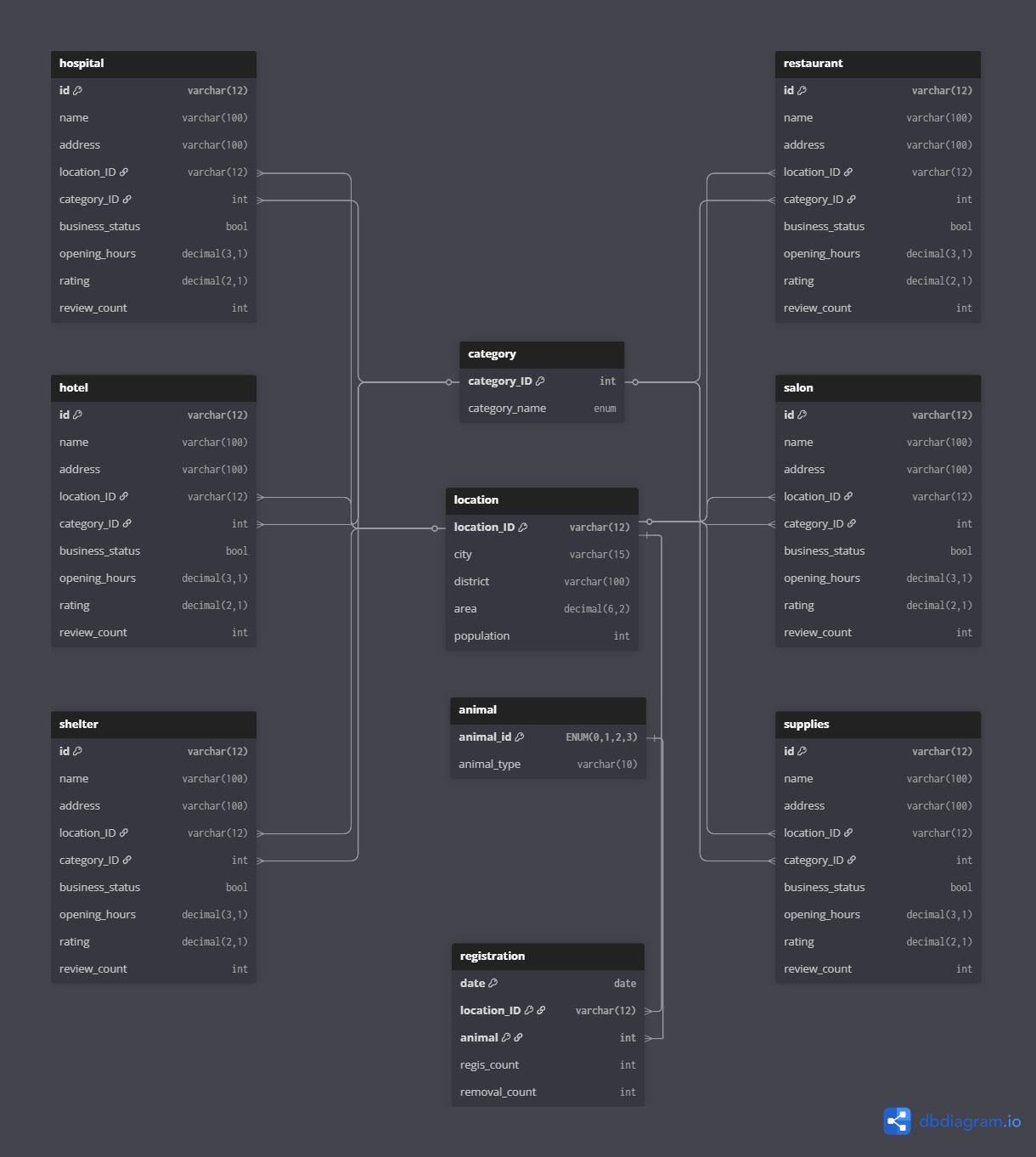
1. 事實表 (Fact Tables / Main Tables)
包含 restaurant, supplies, hotel, hospital, salon, shelter 等六大店家表,以及 registration 寵物登記表。
- 內容:儲存具體的業務數據,如營業時數、評論數、評分、經緯度等。
- 特性:資料會隨時間變動(日更或月更),分析時會彙整這些表進行運算。
2. 維度表 (Dimension Tables / Lookup Tables)
包含 location (地區表), category (類別表), animal (寵物種類表)。
- 內容:儲存相對穩定的描述性資料(如行政區名稱、店家分類定義)。
- 用途:作為事實表的關聯依據,方便進行維度切片分析。
ETL/ELT 流程
流程圖示
graph TD
%% --- 定義樣式類別 (Styles) ---
classDef source fill:#FFEDCC,stroke:#E69138,stroke-width:2px,color:#333333,font-weight:bold;
classDef storage fill:#D0E0E3,stroke:#45818E,stroke-width:2px,color:#333333;
classDef process fill:#FFF2CC,stroke:#F1C232,stroke-width:2px,color:#333333;
classDef details fill:#F3F3F3,stroke:#999999,stroke-width:2px,stroke-dasharray: 5 5,color:#666666;
%% --- 主流程節點 (Main Nodes) ---
A[資料來源
Web / Google Maps]:::source B(Data Lake
GCS / Local):::storage C(資料清洗
Pandas):::process D[(Data Warehouse
MySQL)]:::storage %% --- 連結與流程 (Links) - 加粗2px --- A ==>|Python Scripts| B B ==>|Extract & Transform| C C ==>|Load| D %% --- 細節說明 (Detached Subgraph) --- subgraph TransformationDetails [資料處理細節] direction TB C1[Place ID 獲取]:::details C2[欄位標準化]:::details C3[地址解析]:::details C4[營業時間計算]:::details C1 --> C2 C3 --> C4 end %% 使用虛線將主流程與細節連結 C -.-> TransformationDetails %% --- 自訂樣式 --- linkStyle 5 stroke:,stroke-width:4px,stroke-dasharray:4 5 %% 隱藏 subgraph 內部箭頭,只保留緊密排列 linkStyle 3 stroke:none linkStyle 4 stroke:none
Web / Google Maps]:::source B(Data Lake
GCS / Local):::storage C(資料清洗
Pandas):::process D[(Data Warehouse
MySQL)]:::storage %% --- 連結與流程 (Links) - 加粗2px --- A ==>|Python Scripts| B B ==>|Extract & Transform| C C ==>|Load| D %% --- 細節說明 (Detached Subgraph) --- subgraph TransformationDetails [資料處理細節] direction TB C1[Place ID 獲取]:::details C2[欄位標準化]:::details C3[地址解析]:::details C4[營業時間計算]:::details C1 --> C2 C3 --> C4 end %% 使用虛線將主流程與細節連結 C -.-> TransformationDetails %% --- 自訂樣式 --- linkStyle 5 stroke:,stroke-width:4px,stroke-dasharray:4 5 %% 隱藏 subgraph 內部箭頭,只保留緊密排列 linkStyle 3 stroke:none linkStyle 4 stroke:none
關鍵轉換邏輯 (Transformation)
從 API 獲取的原始 JSON 資料需經過清洗才能進入資料庫:
- ID 生成:為各類別生成易讀的主鍵(如
hotel->htl0001)。 - 地址解析:將原始地址字串利用 Regex 解析出
City與District,並映射至對應的loc_id,處理格式不一致(如缺漏城市名)的問題。 - 經緯度提取:從巢狀 JSON 解構出
longitude與latitude。 - 營業時數計算: Google Maps 提供的是文字格式的「營業時間區間」,我們需將其轉換為可量化的「每週總營業時數」。
# 原始資料範例
# [ "星期一: 10:00 - 18:00", "星期六: 休息", ... ]
def calculate_weekly_hours(raw_schedule):
# 1. 使用 split/replace 清洗文字
# 2. 解析時間字串為 datetime 物件
# 3. 計算每日時數並加總
return total_hours # e.g., 40.0
Airflow 自動化設計
架構總覽
- 規模:共建立 16 支 DAGs(12 支資料處理、3 支分析計算、1 支備份維護)。
- 容錯機制:內建 3 次 Retry 機制,並配置 SMTP Email 報警系統。
DAG 設計原則:模組化與單一職責
為了提高維護性,我們遵循以下原則:
- 原子化 Task:將大流程拆解為獨立函式,每個 Airflow Task 僅負責單一職責。若發生錯誤,可精確定位並僅重跑該節點,無須全流程重來。
- 參數序列化:因應 Airflow Task 間的通訊限制,變數皆封裝為
dict並序列化傳遞,提高可讀性。 - 程式碼重用:店家資料處理邏輯高度相似,我們建立共用 Module,DAG 僅需引用並傳入不同參數即可,大幅減少重複程式碼。
- 安全性:使用
PyMySQL連線,並將機敏資訊(IP, Password)抽離至.env環境變數檔,嚴禁寫死在程式碼中。
雲端部署與 CI/CD
雲端基礎建設 (Infrastructure)
- 運算資源:GCP Compute Engine (VM)。
- 儲存資源:Google Cloud Storage (GCS) 作為 Data Lake 及備份。
- 環境標準化:全面導入 Docker,確保開發環境(Local)與生產環境(Cloud)的一致性,並以容器化方式運行 Airflow 與 MySQL,確保 24/7 服務不中斷。
安全性實踐
- IAM 權限控管:建立專用 Service Account,並透過 IAM 賦予最小權限原則。
- 網路防火牆:
- 配置 Firewall Rule 拒絕所有 ICMP 連線,防禦基礎網路掃描與攻擊。
- 僅開放必要 Port(如 MySQL 對外服務端口),並限制來源 IP。
CI/CD 策略
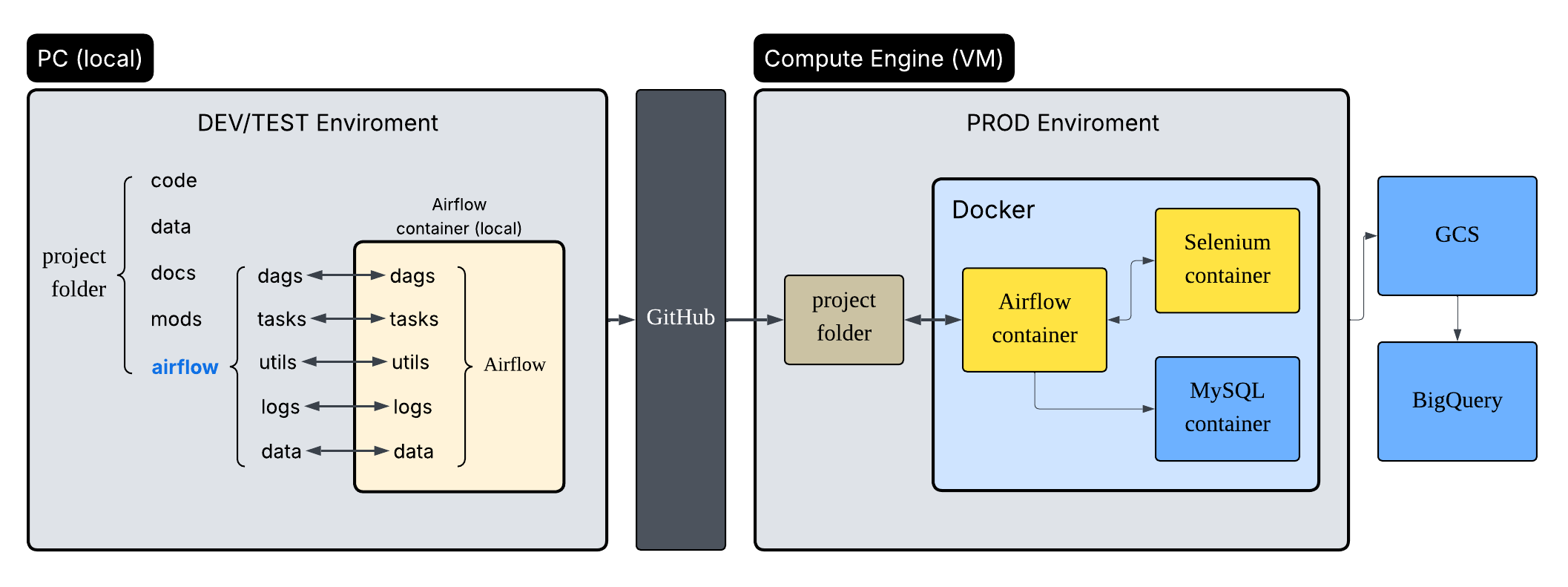
- 持續部署 (CD):利用 GitHub Actions 建立 Pipeline。當 Master 分支更新時,自動觸發流程,透過 SSH 連線至 VM 拉取最新程式碼並重啟容器。
- 流程考量:
- 雖然 Docker 統一了環境,但 CI/CD 能進一步消除「手動部署」帶來的人為失誤與時間成本。
- 考量專案時程與穩定性,目前採用「手動觸發」部署的方式,在確保版控內容正確後才執行更新,平衡了自動化效率與發布風險。
資料分析與視覺化
統計運算:SQL 與 Python 的協作
我們採用雙軌並行的方式處理數據指標:
- SQL (主要):90% 的運算直接在資料庫層透過 SQL 完成,並建立 View 儲存中繼資料,確保數據即時性。
- Python (輔助/自動化):針對 SQL 較難處理的統計(如百分位數),或需整合進 Airflow 排程的複雜運算,則使用 Pandas 處理並寫回資料庫。
互動式儀表板
最終成果透過 Tableau 呈現,將「寵物便利度」與「商業潛力」轉化為直觀的地圖與圖表:
- 寵物便利度指標 Dashboard:供飼主查詢。
- 商業潛力指標 Dashboard:供業者評估。
最後編輯於 2026-01-02